こんにちは。WebディレクターのNです。
普段、ファイルの中に記述されているキーワードや文字列を抽出したいとき、皆さんはどのように検索していますか?まずはファイルを開いてショートカットキーCtrl+F(またはCommand+F)で検索してます、という方がほとんどかと思いますが、
例えば、
・そもそもどのファイルに目的の文字列が記述されているかわからない
・検索対象のファイルが大量にある
こんなケースの場合、ファイルを一つ一つ開いて検索…をひたすら繰り返すのはなかなか大変な作業ですよね。
そこで今回は、Grep検索なを使って、より効率的に特定の文字列を抽出する手順を紹介してみたいと思います。
それではさっそくいってみましょう!
目次
——————————–
1.Grep検索とは
2.検索の手順
3.まとめ
——————————–
{1.Grep検索とは}
手順紹介の前に、まずは自分への忘備録もかねてGrep検索とはなんぞや?ついてまとめておきます。
Grepとは「Global Regular Expression Print」の略称で、文字通り「 (Global) ファイル全体から / (Regular Expression) 正規表現*に一致する行を / (Print) 表示」する検索プログラムのことです。
|
*正規表現とは 検索する文字列を「パターン」で表現する方法です。 [犬] Grep検索結果では「犬」が含まれているファイルの文字列が抽出されます。 |
参照元:Wikipedia
{2.検索の手順}
今回はサンプルとして、Webサイトで構築したアーカイブファイルの中から「iframe」タグを組み込んでいるファイルのみを抽出してみたいと思います! ※PC環境はWindows10Pro、テキストエディタは「秀丸」を使用しました。
① まずは秀丸エディタを起動し、メニューの「検索」から「grepの実行」を選択。
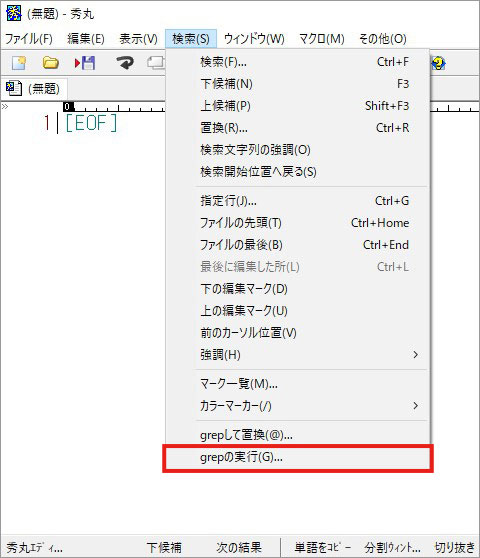

② grepのダイアログボックスが表示されます。
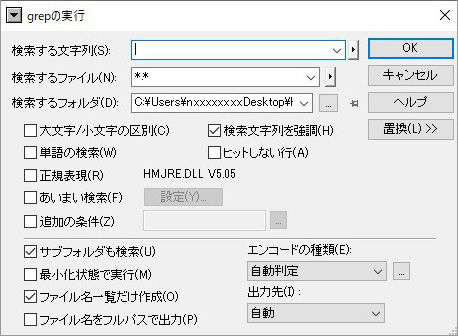

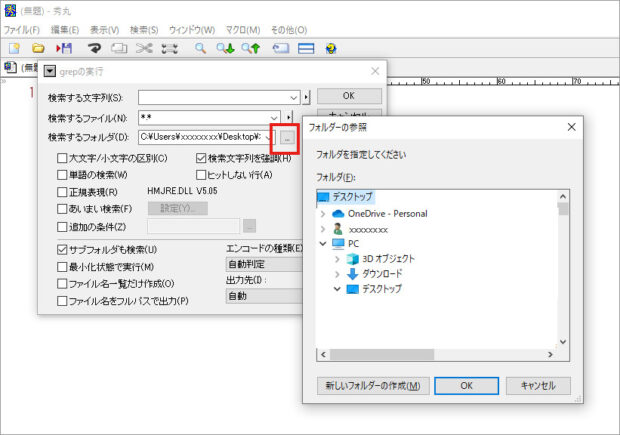
③ 次に、検索したいファイルが格納されているフォルダの階層を選択します。

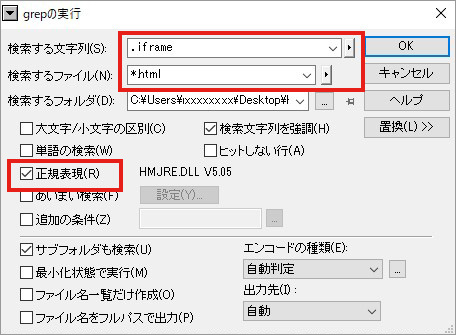
④ 検索する文字列、検索するファイルを指定し、正規表現のチェックボックスをONにします。
サンプルでは正規表現を次のように指定しました。
|
検索する文字列–.iframe(正規表現–.(ピリオド)を使って、iframeという任意の一文字を検索) 検索するファイル–*html |

⑤「ON」ボタンをクリックすると、検索結果が一覧表示されます。
リストの並び順はこんな感じです。
|
ファイル名+行数+半角空白+検索キーワード(黄色ハイライト)が含まれている行 |
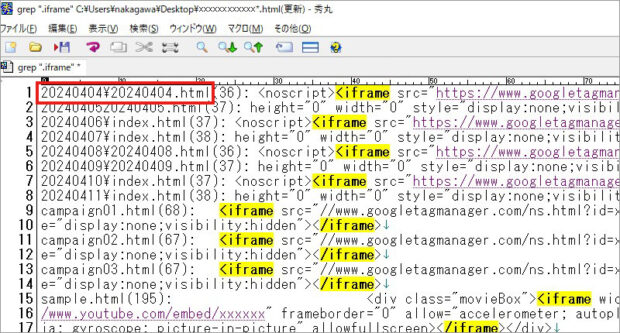

⑥ さらに、文字列(赤枠)をダブルクリックすると抽出元のファイルを開くことができます。
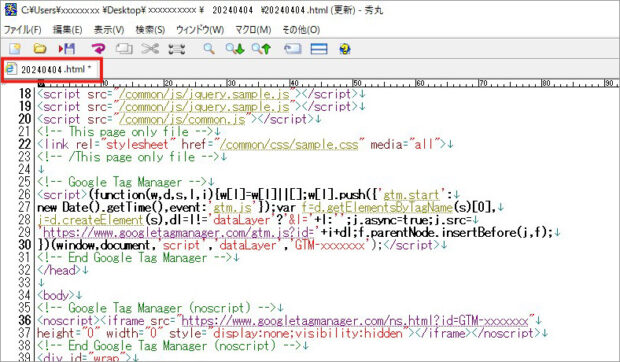

具体的にソースの記述を確認することができるので、便利ですね…
{3.まとめ}
以上、Grep検索の手順でした。いかがでしたでしょうか?
正規表現をつかうと、色々な多文字列のパターンを抽出検索することができるのですが、慣れないうちは、どのように指定をすればよいかわからないと思います。まずは今回のサンプルのように、シンプルな1文字検索あたりから初めてみてはいかがでしょうか。
正規表現の動作チェックができる便利ツールもありますので、ぜひ活用してみてくださいね。
▼初心者向け・おすすめ正規表現チェックツール
WEB ARCH LABO Tools様
正規表現チェッカー様
今回の記事がみなさまのお役に立てれば幸いです。
それではまた!






