上手に使って効率アップ!画像の文字をテキストデータに変換してくれる便利ツールのご紹介
日本語のサイトを多言語に翻訳する際に、まず日本語の原稿を揃える作業がありますが、原稿が存在しないで、画像中のテキストしか残っていない、というようなことが良くあります。最近ではブラウザのプラグインなどでOCRのツールも多くあり、人によって使いやすいものは違うかもしれませんが、個人的にオススメのGoogleドライブを使ったテキスト抽出方法をご紹介したいと思います。
抽出方法
1)テキストの入った画像をGoogleドライブでアップします。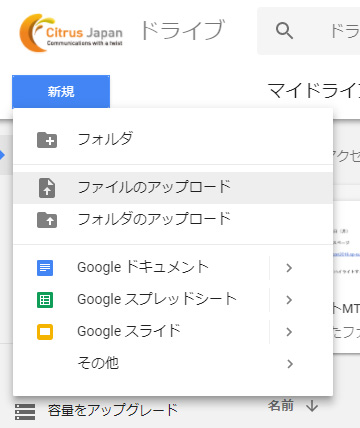
2)このように、アップされた画像が表示されます。
3)プレビューウィンドウを一旦閉じて、アップしたファイルを右クリック。「アプリで開く」から「Googleドキュメント」を選択します。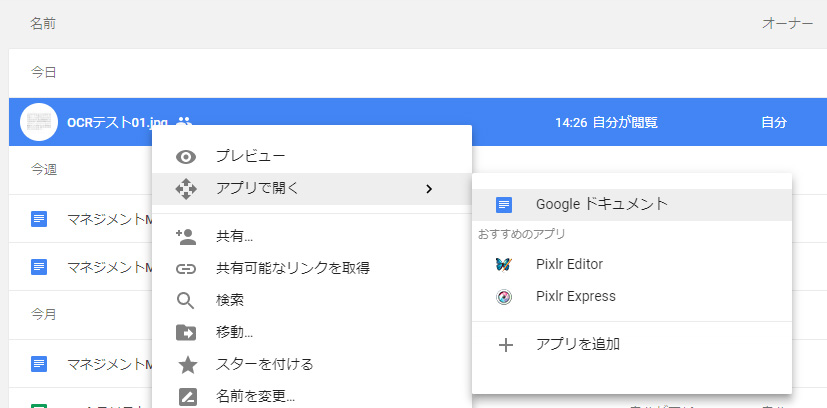
4)Googleさんが、くるくる少し考えた後に、画像の下に抽出されたテキストが表示されます。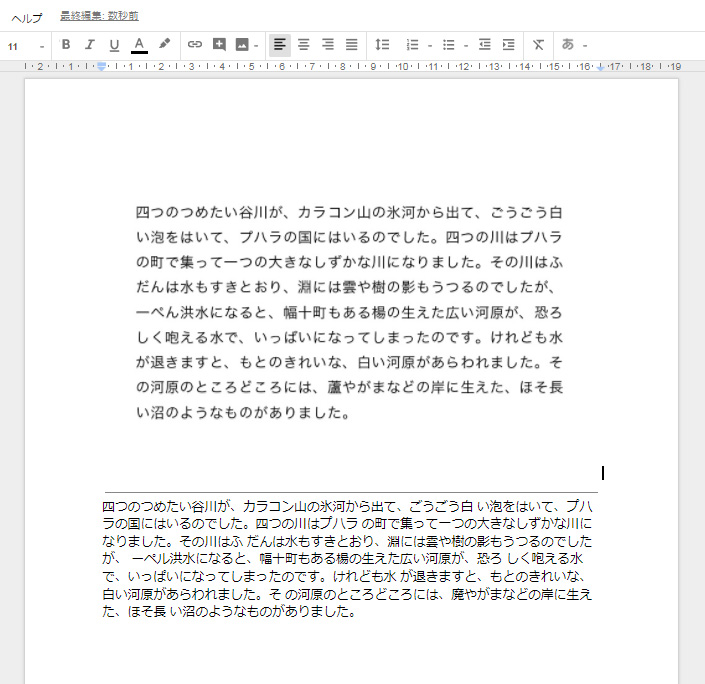
これは便利!!
ん? でもよく見ると・・・ちょっと怪しいですね。
フォントの違いや文字の薄さ、画像に乗っている状態でどのくらい正確に抽出してくれるか実験してみました。
テキスト化の正確さの実験
準備したのは、以下の4点のフォントです。
①白地に黒文字のゴシックフォント
②白地にグレー文字のゴシックフォント
③白地に黒文字の明朝フォント
④画像背景に白地のゴシックフォント ※シャドーで可読性は上げています
この4点をGoogleドライブでテキスト抽出をして、元原稿と比較ツールで比べてみました。
①白地に黒文字のゴシックフォント


かなり正確にテキスト化してくれてますが、改行部分には半角スペースが入ってしまうようです。また画数の多い漢字は要注意ですね。
②白地にグレー文字のゴシックフォント


文字色が薄くてもこれくらいなら、黒文字とあまり変わりません。ただ、濁点のありなしは、しっかり校正しないと見逃してしまいそうです。
③白地に黒文字の明朝フォント


明朝でもゴシックでも結果はほぼ変わりません。
④画像背景に白地のゴシックフォント


画像に乗ってこれくらい読みにくいとさすがにエラーの数がグッと増えます。しっかり校正する必要がありますね。
個人的には、「蘆(よし)」という漢字を、「魔」「蔵」「意」といろいろなバージョンで間違えるところに、昔のワープロ誤変換みたいな可愛らしさを感じます。
結論
作業の効率化を上げてくれる便利ツールですが、完全に任せてしまうと思わぬミスにつながってしまいます。その特性を把握して上手に使い、作業をスピードアップしていきましょう。